
Hoje as redes sociais são as principais fontes de informação sobre os hábitos dos consumidores. É possível extrair os mais variados tipos de dados sobre diversos assuntos (eleições, esportes, reality shows, etc.) de redes como Facebook, Twitter, Instagram, Youtube, Snapchat, dentre tantas outras, com a ajuda de um único software de monitoramento.
Normalmente, o pontapé inicial desse monitoramento acontece ao definir termos de busca que trazem publicações relevantes sobre os tópicos pelos quais estamos interessados.
Dados capturados por esse tipo de software são depois filtrados, fatiados, picados e ainda avaliados por analistas que os transformarão em relatórios inteligentes para os profissionais de marketing.
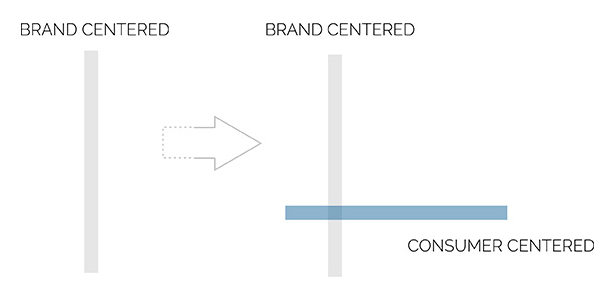
O problema é que muitos desses reports estão focados numa só questão: “o que as pessoas dizem sobre a minha marca?”, quando na verdade deveria ser “quem são os consumidores influentes da minha marca?”.
Ao mudar a pergunta de o quê para quem pretendemos acrescentar à tradicional abordagem de monitoramento uma dimensão inteiramente nova, focada no consumidor.
Deep Profile
Quando perguntamos quem são os consumidores relevantes para uma marca queremos conhecer esses indivíduos ao nível mais profundo possível. Nosso objetivo é produzir de forma continua um perfil detalhado, ou deep profile, de cada pessoa. Em condições ideais espera-se que o deep profile de cada user esteja em constante evolução. Além disso iremos atribuir, na medida do possível, um novo significado a informação pública disponível sobre esse consumidor, que até então existia apenas de modo desestruturado e solto. Por exemplo:
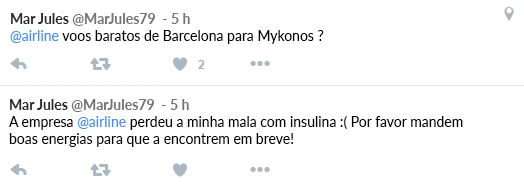
O que descobrimos? O primeiro tweet revela que Mar Jules transporta insulina e o segundo que ela quer visitar a Grécia. Devemos, então, armazenar essas informações num deep profile de modo que possamos consultá-las novamente mais tarde. Assim teríamos: @MarJules79 mencionou #Insulina e #Mykonos. Podemos renovar essas informações de forma simples através de uma lista de termos relacionados ao âmbito do tema em foco inseridos em nossa ferramenta de monitoramento.
Existem outros lugares onde podemos encontrar informações relevantes sobre um usuário. Por exemplo o campo bio:
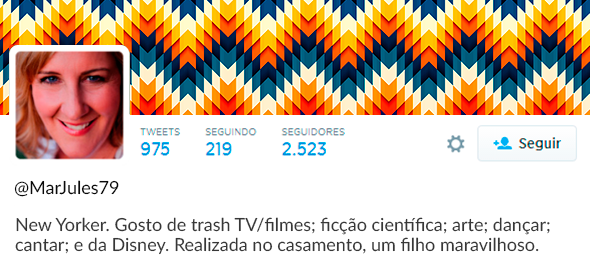
Encontramos novas informações para serem integradas ao deep profile de Mar Jules: #NewYorker, #trashTV, #trashMovies, #scifi, #art, #dancing, #singing, #Disney, #married, #son.
É importante observar como o processo de geração de um deep profile não é estático: cada novo tweet da @MarJules79 demonstra uma potencial evolução em seu perfil.
Como acrescentar timelines do Twitter e fazer a análise do deep profile
Como foi mostrado na seção anterior, o deep profile é o principal bloco de construção na geração de insights e no processo de descoberta do nosso consumidor. Para a produção de deep profile, em vez de monitorarmos menções a determinada marca, iremos armazenar toda a timeline de um grupo de consumidores. É fundamental percebermos essa distinção uma vez que somos condicionados a monitorar menções a marcas, pois agora trata-se de algo fundamentalmente novo: iremos olhar, pela primeira vez, para as timelines inteiras dos consumidores.
Isso significa que os nossos projetos de monitoramento de redes sociais com o Buzzmonitor armazenarão todos os tweets de um grupo de usuários e não apenas os tweets mencionando uma determinada lista de palavras.
Um projeto de monitoramento centrado no consumidor é dividido em duas fases principais:
- Estabelecer critérios iniciais para a seleção de um grupo de usuários do Twitter (mães, adolescentes, amantes de vinho, etc);
- Carregar bases de dados do Buzzmonitor com centenas de tweets do consumidor correspondente para cada timeline. Chamamos essa capturação de dados de tweets não-filtrados de Painel de Consumidores.
O tamanho habitual de um Painel de Consumidores do Buzzmonitor é de mil a 1.200 pessoas. Carregamos de 500 à 1.000 tweets da timeline de cada usuário, o que nos deixa com cerca de 500 mil a 1 milhão de itens. No entanto, o tamanho da base de dados pode ser muito maior do que isso, dependendo exclusivamente do grau de profundidade e do orçamento de cada projeto.
Organizar o Big Data dos consumidores no Twitter
Aqui utilizaremos um dos painéis de consumidores composto por 5.000 australianos selecionados aleatoriamente como exemplo. Trata-se, principalmente, da criação de relatórios com base em termos que identificam comportamentos e ações dos consumidores. Por exemplo, você pode começar com verbos como: “observar”, “beber”, “comer”, “ter”, “adquirir”, “comprar” – e ainda incluir a variação de tempos verbais.

No primeiro gráfico procuramos o termo “ver”, depois os termos mais frequentes na totalidade desses tweets. Existem 195 menções a hashtag #bbau, que se refere ao Big Brother Austrália. A hashtag #theblock refere-se a outro reality show australiano e tem 69 menções.
Estes dados podem ser ainda filtrados de modo a isolarem mais atributos, tais como sexo ou bio.

Aqui vemos a distribuição de gênero em uma amostra de pessoas onde os termos “ver” e “jogo” foram mencionados. Desse público, 8% eram homens e 25% mulheres (os campos desconhecidos correspondem a nomes de usuários impossíveis de classificar).
Em seguida, vamos olhar para bebidas populares como Coca-Cola, Pepsi, cerveja, vinho e café. Criamos um relatório para cada bebida e mapeamos a evolução do volume de menções dentro da nossa base de consumidores.
Os resultados abaixo referem-se a café:

Vemos uma tendência interessante: as menções ao termo “café” tendem a duplicar ou triplicar durante os finais de semana (sexta e sábado). Podemos claramente observar os picos de volume no gráfico nesses dias. Entretanto não podemos afirmar que o consumo de café aumenta aos fins de semana, mas não deixa de ser uma informação valiosa para qualquer pessoa que trabalhe na área de vendas de café: o fim de semana é o período ideal para promover um produto ou serviço no Twitter.
O Buzzmonitor disponibiliza uma série de relatórios semelhante aos que fazem parte das ferramentas clássicas de Business Intelligence, além de permitir ao analista gerar quantos relatórios quiser. Ao combinar termos de busca selecionados, torna-se possível gerar relatórios sobre qualquer tópico que possa emergir no fluxo a partir da nossa base de consumidores.
No exemplo, observamos menções a cerveja, café, vinho, chocolate, frango e bacon:
As bios do Twitter
O campo Bio do Twitter é muitas vezes negligenciado. Mas, na verdade, é uma excelente maneira de coletar dados demográficos.
Uma vez removidas as brincadeiras, o que sobra são verdadeiras preciosidades que nos dizem tudo sobre o consumidor, desde a profissão até seu estado civil. Você pode usar o Buzzmonitor para filtrar palavras específicas do campo Bio, como “música”, “vegan” ou “fã de carros”, podendo ainda gerar os termos mais frequentes nesse campo que lhe oferecerão um ponto de partida para conhecer melhor a demografia do assunto pesquisado.
Por exemplo essa coleção de bios de pessoas que mencionaram vinho. Mesmo sem uma análise profunda é possível fazer algumas associações: comida, café e cerveja são também mencionados em bios relacionadas a vinho. “Marido” (homens) e “Melbourne” vêm logo depois, seguidos por “cricket”.

Por onde começar?
Digamos que você está prestes a lançar uma nova marca de iogurte de soja. Você já sabe, através de pesquisas de mercado tradicionais, que a maioria do seu público é composto por mulheres moradoras de Melbourne e Sydney. Como você pode descobrir mais sobre este público-alvo no Twitter?
Primeiro você deverá desenhar uma busca clássica de monitoramento de redes sociais selecionando termos falados por esse grupo demográfico. No caso do iogurte de soja, os termos “iogurte”, “lactose”, “vegan”, “vegetariano” e “alimentação biológica” parecem ser um bom ponto de partida.
Assim que tiver dados suficientes (tipicamente entre 20.000 a 40.000 tweets), você estará pronto para filtrar uma amostra de usuários de acordo com os critérios estabelecidos: mulheres de Sydney e Melbourne.
Nesse momento você poderá até utilizar filtros mais fortes, como: pessoas da amostra que mencionaram lactose duas vezes ou pessoas que se declararam vegans no campo Bio. Cabe a você aplicar as restrições que quiser a sua lista de usuários de modo a tornar a pesquisa mais precisa ou mais genérica, dependendo dos seus objetivos. Uma vez que tenha em mãos a sua lista de consumidores, nós estaremos prontos para ajudá-lo a construir o seu primeiro Painel de Consumidores.
Dê início ao seu próprio Consumer Panel
Os consumidores querem ser ouvidos. Pensando nisso, o Buzzmonitor automatizou o processo de escutar os consumidores de forma bi-dimensional: você não só ouvirá as conversas sobre a sua marca como ouvirá todas as conversas que o seu target tenha. Num mundo em que a atenção é escassa, saber refinar as suas mensagens através de um melhor conhecimento do seu consumidor torna-se uma grande vantagem competitiva.
